本年 10 月porn 国产,智谱在 CNCC2024 大会上推出了他们在多模态范围的最新服从——端到端心扉语音模子 GLM-4-Voice,让东谈主和机器的疏导大致以当然聊天的景色进行。
以下为他们在官方 GitHub 上给出的 demo。
先用北京话念一句急口令。
据先容,GLM-4-Voice 大致平直融会和生成中英文语音,进行及时语音对话,在心计感知、心扉共识、心计抒发、多说话、多方言等方面杀青破损,且延时更低,可随时打断。
日前,来自清华大学和智谱的征询团队发布了 GLM-4-Voice 的征询论文,对这一端到端语音模子的中枢工夫与评估结果进行了详备答复。
GLM-4-Voice 是如何炼就的?
与传统的 ASR + LLM + TTS 的级联有筹算比拟,端到端模子以音频 token 的面目平直建模语音,在一个模子内部同期完谚语音的融会和生成,幸免了级联有筹算“语音转翰墨再转语音” 的中间流程中带来的信息亏蚀,也解锁了更高的才调上限。
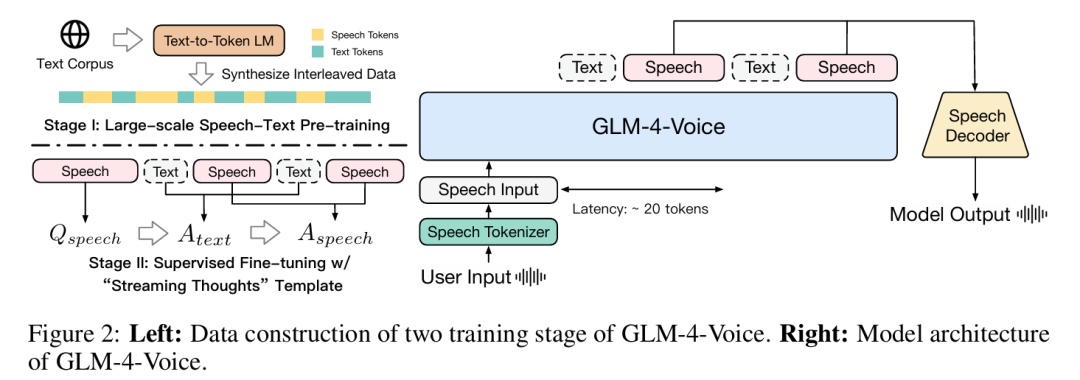
GLM-4-Voice 由三个部分构成:
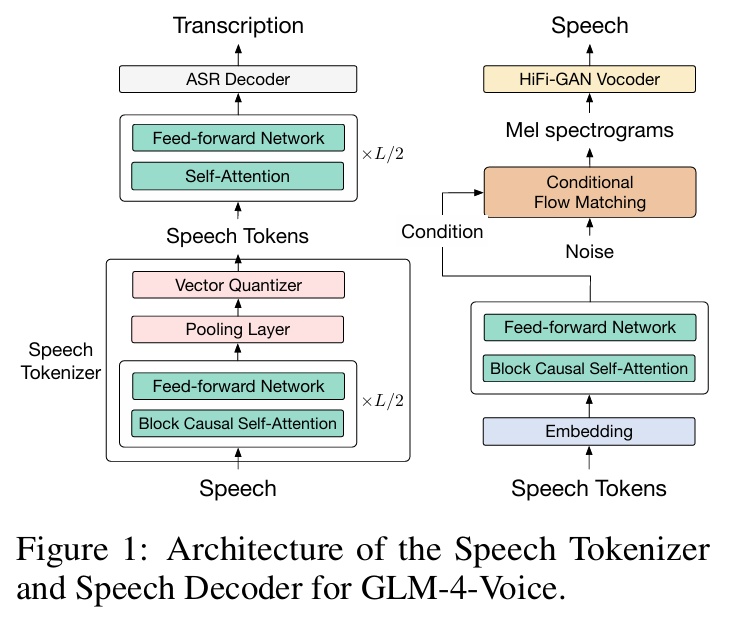
GLM-4-Voice-Tokenizer:通过在 Whisper 的 Encoder 部分加多 Vector Quantization 并在 ASR 数据上有监督锤真金不怕火,将络续的语音输入调治为翻脸的 token。每秒音频平均只需要用 12.5 个翻脸 token 暗示。
GLM-4-Voice-Decoder:基于 CosyVoice 的 Flow Matching 模子结构锤真金不怕火的救助流式推理的语音解码器,将翻脸化的语音 token 调治为络续的语音输出。最少只需要 10 个语音 token 即可运转生成,缩小端到端对话蔓延。
GLM-4-Voice-9B:在 GLM-4-9B 的基础上进行语音模态的预锤真金不怕火和对皆,从而大致融会和生成翻脸化的语音 token。
预锤真金不怕火方面,为了攻克模子在语音模态下的才略和合成领会力两个难关,他们将 Speech2Speech 任务解耦合为“凭证用户音频作念出文本回应”和“凭证文本回应和用户语音合成回应语音”两个任务,并设想两种预锤真金不怕火标的,区分基于文本预锤真金不怕火数据和无监督音频数据合谚语音-文本交错数据以适配这两种任务面目。
具体而言,模子的预锤真金不怕火包括 2 个阶段。
第一阶段为大范围语音-文本融合预锤真金不怕火,在该阶段中 GLM-4-Voice 领受了三种类型的语音数据:语音-文本交错数据、无监督语音数据和有监督语音-文本数据,杀青了促进文本和语音模态之间常识迁徙、匡助模子学习真确全国语音特征以及晋升模子基本任务方面性能方面的效果。尤其,GLM-4-Voice-9B 在 GLM-4-9B 的基座模子基础之上,经过了数百万小时音频和数千亿 token 的音频文本交错数据预锤真金不怕火,领有很强的音频融会和建模才调。
第二阶段为监督微调阶段,旨在进一步提高 GLM-4-Voice 的对话才调。征询东谈主员使用了两种类型的对话数据,包括多轮对话数据与语音作风截止对话数据。前者主要来自文本数据,经过全心筛选和语音合成,确保对话本色的质料和万般性。此后者包含高质料的对话数据,用于锤真金不怕火模子生成不同作风和语调的语音输出。
此外,在对皆方面,为了救助高质料的语音对话,缩小语音生成的蔓延,征询团队设想了一套流式念念考架构:凭证用户语音,GLM-4-Voice 不错流式瓜代输出文本和语音两个模态的本色,其汉文音模态以文本手脚参照保证回应本色的高质料,并凭证用户的语音提醒条目作念出相应的声息变化,在最猛进度保留说话模子才略的情况下仍然具有端到端建模的才调,同期具备低蔓延性,最低只需要输出 20 个 token 便不错合谚语音。
效果如何样?
征询团队在基础模子评估与聊天模子评估两方濒临 GLM-4-Voice 进行了性能评估。
他们着手通过语音说话建模、语消息答以及 ASR 和 TTS 这三项任务对基础模子进行了评估。
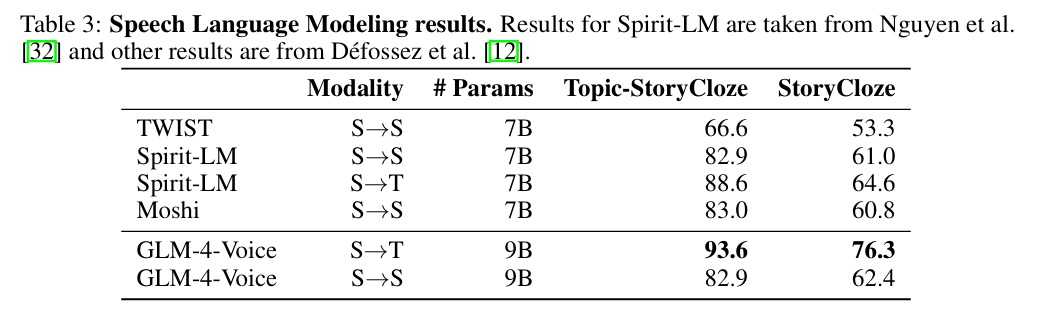
在语音说话建模任务中,GLM-4-Voice 在 Topic-StoryCloze 和 StoryCloze 等数据集上的准确率显耀最初同类模子。在从语音到文本生成(S→T)的任务中,GLM-4-Voice 的准确率达到 93.6%(Topic-StoryCloze),远高于其他模子。同期,在语音到语音生成(S→S)的任务中,GLM-4-Voice 已经在 Topic-StoryCloze 数据连合赢得了与 Spirit-LM 独揽的高分(82.9%)。
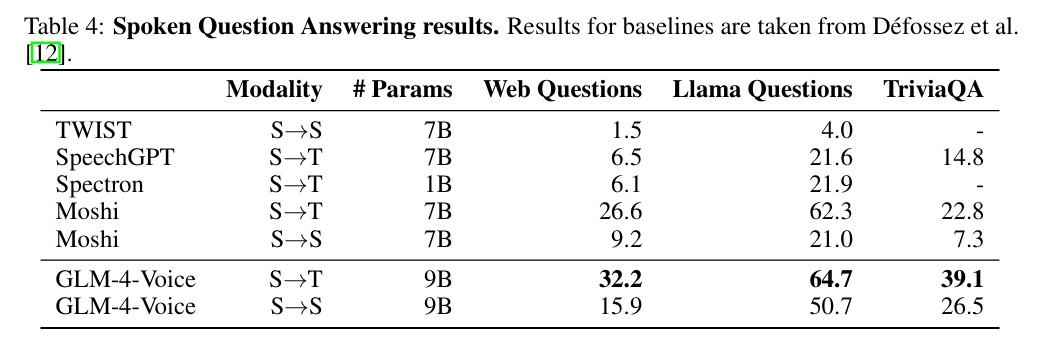
在语消息答任务中,GLM-4-Voice 在 Web Questions、Llama Questions 和 TriviaQA 等数据集上全面最初,进一步晋升了模子在长险阻文交互场景中的妥当性。
S→T 模态:在所罕有据连合,GLM-4-Voice 均显耀最初基线模子,TriviaQA 数据连合准确率达到 39.1%,比拟Moshi晋升了 16.3%。
S→S 模态:在语音到语音的问答任务中,GLM-4-Voice 雷同领会优异,尤其是在 Llama Questions 中准确率达到 50.7%,大幅最初其余模子。
在 ASR 和 TTS 任务中,GLM-4-Voice 的性能也雷同接近或卓绝挑升设想的语音解决模子。
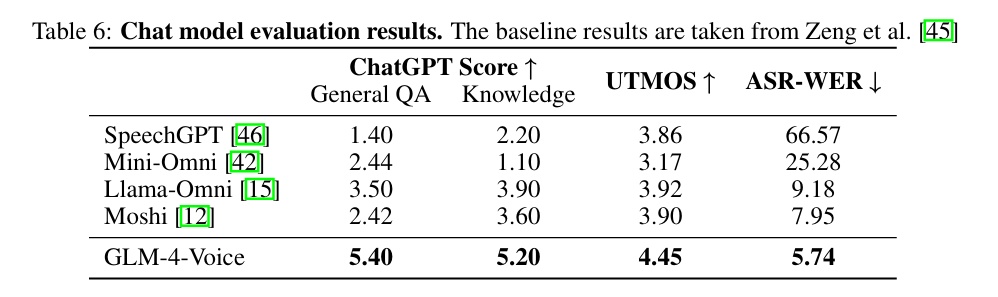
海选av女优之后,征询团队对聊天模子进行了评估。
为评估对话质料,征询团队引入 ChatGPT 手脚自动评分器具,对模子的回答进行多维度评价。GLM-4-Voice 在常见问题(General QA)和常识问答(Knowledge QA)两类任务中得分遥遥最初:在 General QA 中 GLM-4-Voice 得分为 5.40,比拟 Llama-Omni(3.50)和 Moshi(2.42)晋升显耀。在 Knowledge QA 中 GLM-4-Voice 的得分雷同最初其他模子。
GLM-4-Voice 在语音生成质料方面也杀青了新破损。模子主不雅评价筹算(MOS)的评分中达到 4.45,卓绝现存基线模子,标明 GLM-4-Voice 生成的语音愈加当然通顺,大致知足用户对高质料语音交互的需求。
同期,在文本与语音对皆性测试中,GLM-4-Voice 的语音转文本罪过率(ASR-WER)降至 5.74%,表示出优异的文本-语音一致性。这种才调进一步晋升了模子在多模态交互中的哄骗后劲。
评估结果表示,GLM-4-Voice 在语音说话建模、语消息答等任务上领会不凡,同期大幅缩小了蔓延,并显耀晋升了语音质料和对话才调,性能最初现存基线模子。这一转换为构建高性能语音交互系统提供了全新旅途,开拓了更平日的哄骗可能性。
当今,GLM-4-Voice 已开源porn 国产,当今已有 2.4k stars。征询团队暗示,这将饱读吹东谈主们进一步探索开采实用、易用的语音东谈主工智能系统。
Powered by 苍井空A级在线观看网站 @2013-2022 RSS地图 HTML地图
Copyright Powered by站群 © 2013-2024